
Hello! This article is now outdated, but we're leaving it up for posterity. Visit tractorbeam.me for the latest information on how to backup your Drupal 8, Drupal 9, Wordpress or any other site that has files and uses MySQL.
Since its introduction, NodeSquirrel was the go-to solution for Drupal off-site backup. As a developer, you would only need to install the Backup and Migrate module, create a NodeSquirrel account, and you’d be set! So naturally, it’s what we reached for when our client’s brand new site need automated backups last Fall.
And That’s When We Ran Into a Snag
The client’s site was running on Drupal 8. While there was a Backup and Migrate module for Drupal 8, it was currently in development and had no stable release. Worse, there was no NodeSquirrel support at all! Not wanting to disappoint the client, we built our own off-site backup solution.
As part of our Continuous Integration process, we take a backup of each site prior to deploying a new one. This way, if there is ever a build failure, we can easily roll back. Our ten7.drupal-backup Ansible role creates an archive of the site code, the configuration sync directory for Drupal 8 sites and a database dump. With a bit of ingenuity, I thought, we could use that backup role and create an off-site version that could be uploaded to Amazon S3.
Today, we’ve built out that solution and deployed it to all our production sites.
Introducing Tractorbeam
Tractorbeam uses open source software to create a multi-tier, off-site backup for any MySQL-backed website, including Drupal 6, 7, or 8. No Drupal-specific utilities or code are utilized in Tractorbeam. And Tractorbeam is freely available for use on Ansible Galaxy as ten7.tractorbeam. You can also contribute back to the code on Github.

How Tractorbeam Works
You configure Tractorbeam using Ansible variables. Most importantly, it expects the following:
- Database name and login
- The full path to the site code
- The full path to the file upload directory
- Optionally, the full path to the site’s configuration directory
The Tractorbeam Ansible role takes this information and creates background processes that run daily, weekly and monthly. Each process produces a complete database, site code and configuration directory backup. Old backups are automatically pruned by age, so your server isn’t overrun by backups. It looks a bit like this, which is an example of a snapshot of backups for the TEN7 site:
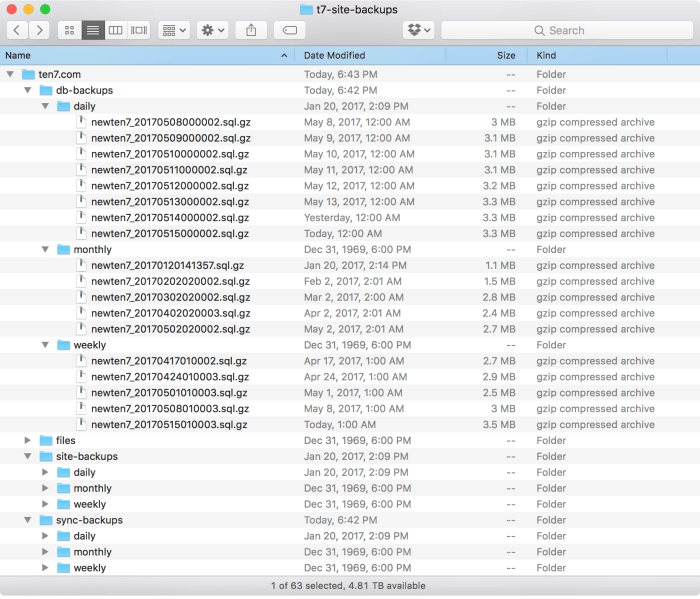
After creating and pruning backups, Tractorbeam uses the aws command to synchronize the backup directories to Amazon S3. Since we delete old backups before uploading to S3, your S3 account isn’t overrun with backups either.
“Wait,” you might be thinking, “What about the file upload directory?” We quickly found out that it’s not practical to create an archive for the file upload directory, as some of our sites have potentially gigabytes of files. Instead, Tractorbeam synchronizes the file upload directory directly to S3. File uploads to websites tend to be cumulative, with only the latest version being the most important. This saves valuable disk space and network bandwidth when running Tractorbeam.
Handling All Kinds of Hosting
For sites running on Infrastructure as a Service (IaaS), Virtual Private Hosting (VPS), Co-located, or internal hosting, Tractorbeam can run on the same system that hosts the website itself. One only needs to install Ansible and the aws. This works great on our own ipHouse-hosted cluster, or our clients running on VPSes like Blackmesh.
Many of our smaller clients choose to use shared hosting to reduce costs. Typically, you can’t install Ansible, the aws, or even run cron on many of these hosts. Thankfully, Tractorbeam can handle this as well! Getting back the client I mentioned at the beginning of the post, we created a backup server using a micro instance on Amazon Elastic Compute Cloud (EC2). In this configuration, Tractorbeam does the following:
- Connects to the shared host via SSH using public keys.
- Creates a new backup, including site code, config directory and database dump.
- It synchronizes the backup directories and the file upload directory to the EC2 instance.
- Finally, it syncs all the local copies of backups and files to S3.
Getting Backups
Tractorbeam doesn’t offer a webUI (yet) but it’s very easy to manage and download your backups from http://console.aws.amazon.com. You can view or download your backups just by going to the S3 section in the console. You can also use SFTP to download the backups from wherever Tractorbeam runs as the files are mirrored there as well.
Summary
Tractorbeam not only solved our offsite, multi-tier backup needs at TEN7, but we did it using free and open source tools. We’re so confident of it, we no longer use Backup and Migrate on any of our sites. You can download both our Drupal Backup role and Tractorbeam on Ansible Galaxy, and contribute documentation, code, or post issues on our Github.
We’d love to help you figure out automated, seamless backups for your own Drupal 8 install, so why not drop us a line so we can talk.
