
We have been running Kubernetes in production for years. In that time, our infrastructure has iterated on the design I set out in my talk, Return of the Clustering.
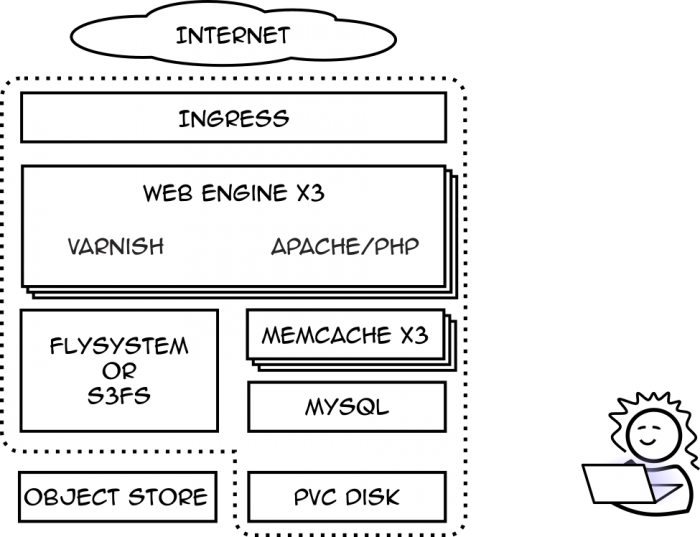
Since then, we’ve added Cert Manager for certificate provisioning from Let’s Encrypt, we dropped Flysystem for S3FS entirely, and we’ve shared MySQL across multiple sites on the same cluster. Even years later, the basic concept of this design still works well and serves up content to multiple Drupal sites.
But... it’s not without its problems.
Oh Right, That Other Content Manager
One of the quiet assumptions of the above architecture is that it assumes you’re only working with Drupal sites. Drupal sites have what I like to call a “strong API” model. That is, the core of the content management system (CMS) performs any and all tasks that are considered a benefit to all sites. If a programmer needs to do something, there’s likely an existing interface within the CMS they can leverage.
This is a great benefit to things like S3 support. If a module, such as S3FS, provides a means to use standard file interfaces to offload static content to S3 rather than the web server, few modules need to know the difference.
The very large and quiet threatening fauna in the room, however, is that other CMS.
When we got our first Wordpress client, we started to run into the limits of our architecture. My hope was all I needed to do was plug in WordPress’s most popular S3 module and instantly everything would be on S3.
It... didn’t work out that way.
Wordpress has a “weak API” model: the core of the CMS tries to do only what’s necessary, and assumes that each site developer can string together all the required functionality either through modification or custom code. Furthermore, each extension to the CMS is more independent and can have vastly different governing processes or Codes of Conduct. The result of which was that the most popular gallery in the Wordpress world, did not support S3 at all. You would need to extensively modify the system itself to support it.
We tried several ways to make S3 work with Wordpress, but none of them worked. What it wanted was locally attached block storage, and that’s what we had to give it.
But How to Scale?
The problem with locally attached storage, as I mentioned in “Return of the Clustering”, was that all cloud providers do not support multiple writers. You can attach one disk to one container instance, but that’s it. This takes away the key purpose of Kubernetes as often you want multiple container instances so load is spread horizontally.
This isn’t a new problem, of course. In traditional hosting, to have multiple web heads you would need to implement shared storage in the form of NFS. The most popular way to create an NFS server is to use the version provided with the Linux kernel. It’s free, well tested, and there are set-up tutorials everywhere. Yet, there are several huge downsides:
- NFS host container must run as root, creating a security risk.
- The NFS host container must also run in Kubernetes privileged mode, creating more security risk.
- The NFS kernel module must also be enabled on the node (server) hosting the containers. This isn’t always the case as some cloud providers restrict which kernel models are available.
- The NFS host container must be a single instance.
I was about to throw in the towel. And spin up a traditional VM to run NFS when I ran across a solution.
Not a Castle, Knight, or a Corvid
Rook.io is a cloud-native, distributed storage clustering solution for Kubernetes. It’s popular, open source, has wide support, and surprisingly, it’s not difficult to install. The key advantage to using Rook is that it allows you to allocate multi-writer virtual disks, and provision them from a preallocated pool of storage. Once allocated, you can mount them in a container like you would any normal Persistent Volume Claim (PVC).
We have been running a Wordpress site on our Kubernetes infrastructure in production for months now using Rook. All the site’s containers share the same virtual disk with no issue. While we’ve been satisfied with it, we haven’t yet moved our existing Drupal sites to Rook storage and off of S3. The next iteration of the TEN7 site, however, will use Rook.
Backups, the Next Generation
Using Rook for file storage creates a new issue for backups. When only using S3, we could use our Tractorbeam project to duplicate files from the “live” bucket to a backup bucket. There’s no easy way to externalize a Rook PVC to be both locally attached storage and S3. To work around this for our Wordpress site, we run Tractorbeam as a cronjob and mount the same PVC the sites use for static assets.
This works, but as more sites switch away from S3 to Rook, we need to start managing these cronjobs so they don’t overwhelm the cluster by running all at the same time. One solution we’re investigating is to integrate with another cloud-native backup solution, Velero.
Velero is an open source k8s backup solution managed by VMWare. While initially intended to back up k8s object definitions, it can be extended to support PVC snapshots, file-level backups via Restic, or custom implementations. In the future, we may integrate with Velero to provide backup jobs for Rook, SFTP, S3, Platform.sh, and Pantheon.
Databases as a Single Point of Failure
To support Rook, we performed multiple upgrades to our clusters from k8s 1.15 to 1.19. Each update was performed in three steps:
- Update the manager node maintained by the cloud provider.
- Update each node in the cluster, sequentially.
- Cleanup.
While k8s allows multiple instances for any application, not all applications support horizontal scaling. The multiple updates allowed us to study where the single points of failure were in our architecture, and one came up again and again:
The database.
By design, we run a single instance of mariaDB as a MySQL database server on each cluster. MySQL is multi-tenant by design, so this allowed us to minimize resource use and keep hosting costs lower. It also introduced a single point of failure. When the upgrade process rebooted the node housing the database container, all the sites on the cluster went down. Usually no more than 5 minutes, but that could be an eternity to a client.
In traditional hosting, the solution would be to set up MySQL replication. When each MySQL replica is on a different server, outage is minimized. You could do this in k8s using the same techniques, but we kept stumbling on bigger issues.
The Flight Deck database container, by default, will create databases and users on startup passed to it in a YAML file. You can still create databases and users interactively, of course, but to make those structures “permanent”, you need to change that YAML file and reboot the container. This resulted in more downtime. Again, usually not more than a few minutes, but combined with the cluster upgrade issue, this was starting to feel like Death From a Thousand Cuts.
“Hello, Operator”
To fix both issues, what we needed was a persistent resident within the cluster that could respond to requests to create databases and users dynamically without rebooting the database container. Furthermore, it needed to aid in the coordination of multiple database containers to form a MySQL replication cluster.
What we needed, as it turned out, was an operator.
An operator is a design pattern for Kubernetes in which, you guessed it, a persistent resident acts as a managing entity. Rook and Velero both rely on the operator pattern, while also relying on a key feature of Kubernetes called Custom Resource Definitions (CRDs).
Instead of editing a configmap passed to the database container on startup, instead we want to just tell Kubernetes, “We want a database named, my_database.”
apiVersion: flightdeck.t7.io/v1
kind: MySQLDatabase
metadata:
name: my-database
spec:
cluster:
name: mysqlcluster-sample
namespace: my-db-namespace
dbName: "my_database"
encoding: "utf8mb4"
collation: "utf8mb4_unicode_ci"
Then the operator could go on and make the database for us. As a CRD, Velero can now back up this definition, allowing us to restore or migrate it later.
Then, we can do the same with users:
apiVersion: flightdeck.t7.io/v1
kind: MySQLUser
metadata:
name: my-user
spec:
cluster:
name: mysqlcluster-sample
namespace: my-db-namespace
username: "my_user"
host: "%"
state: present
privileges:
- database: "my_database"
table: "*"
grant: "ALL"
But, hold on, why should we stop there? What if we just want to tell the operator to make a database cluster for us? Well…
apiVersion: flightdeck.t7.io/v1 kind: MySQLCluster metadata: name: mysqlcluster-sample namespace: my-db-namespace spec: size: 20Gi readerCount: 2
This is what we’ve been working on the last few weeks, The Flight Deck Operator. This operator is still highly experimental, but you can deploy it using Helm and create databases and users using only some Custom Resource Definitions. While we haven’t put the operator into production yet, it does rely on the tried and tested Flight Deck database containers we’ve been using for years.
Conclusion
Databases are just the start. One problem with setting up our Kubernetes hosting solution, is that it requires a lot more expertise and manual integration of systems. This may work for us as an organization, but at TEN7, we want to do more.
What if you could deploy a single helm chart, and you’d have your own hosting solution? No more finding which containers to use or how to set up each one. No more roadblocks about certificates or shared hosting. All with best practices and backups baked in from the start.
That’s where we’re going. The ultimate goal of the Flight Deck operator is to make hosting websites on Kubernetes easy. Keep an eye on our Github repository to follow all the exciting developments!
